xSkrape for SQL Server: A Hosted Solution for
Querying Live Web Data
“With the ability to turn virtually any web API into a ‘SQL queryable’ data source using zero lines of code (and
configuration in many cases), you can certainly think outside the box in
building new solutions or improving existing ones.”
xSkrape for SQL Server is not a new product: we’ve had it available since version 2.0 of SQL-Hero. This would require you to install SQL-Hero, including a fairly involved “server components” installation. With the advent of xkrape.com and a layer that supports the new xSkrape for Excel add-in available in the Microsoft Office Store, we’ve greatly reduced the friction to get up-and-running with xSkrape for SQL Server. You can now download and install the client-side SQL CLR assemblies that are used to enable xSkrape functions in your SQL databases for free. You can do this directly from the web: no need to download and install components that can get outdated, since our installer will offer the latest code, all of the time. It’s not just about “data scraping” (aka “screen scraping” or “web scraping”) too: you can consume data that’s published using web API’s in near real-time, sometimes with “zero effort” beyond providing the web address – we illustrate this in our examples below.
Taking a step back, why might you even want to use xSkrape for SQL Server? Currently if there’s some data that you find useful from the Internet and you’d like to combine it with data in your SQL Server database, you might be using ETL from a tool such as SQL Server Integration Services (SSIS) to make HTTP requests against these sources, parse the returned data, and load it into tables in your database. With that in place, you’d write queries against data stored in tables. This works, but you have some distinct disadvantages:
- Latency. Your loaded data will only be as current as allowed by the frequency that you run your data scraping ETL processes. If you decide the run them frequently to compensate, you might be imposing unneeded load if your queries are not run as frequently. Hosted xSkrape offers the benefit of “just in time” data.
- Complexity. You inevitably have to write code – potentially a lot of it. This in turn burdens your maintenance and support effort. If you find a great tool that does web scraping ETL for you, you’ve still likely got to do mapping and configuration. Does your tool support the features of the XS.QL language? If not, you might be writing more code to deal with scenarios we’ve already thought of and solved – and more will follow.
- Cost. Closely related to complexity, if we can reduce your development and maintenance time, we’re inevitably cutting your development costs as well. You can tailor your use of xSkrape services to maximize data delivery for the lowest possible cost, especially considering that we offer 250 usage credits for free, every 30 days. Some of you will be using it for free, leaving the “big players” to cover our costs.
For the record, you can still use xSkrape for SQL Server as part of your ETL processes, but you have more options available now. For example, you might include xSkrape queries as part of your SQL queries for reports that are run on a schedule – or even for real-time searches when dealing with small data sets. Or you might use it to do some quick, one-off data extraction directly into SQL tables, cutting out ETL tools altogether. Or you might use xSkrape queries as part of your ETL, simplifying it greatly. The possibilities are vast, and please share your ideas with us: we’d love to construct more examples and can even offer help. It’s also worth noting that we currently offer similar capabilities in SSIS components that are distributed as part of SQL-Hero.
Let’s look at an example where we want to join not one but two external data sources in the same SQL query. The first step is to enable xSkrape for SQL Server on both an instance and database level. We can do that by visiting the xSkrape for SQL Server web page, accept the license agreement, and run the Script Generator Tool – either by clicking the “Run Script Generator” button, or the setup.exe download link:
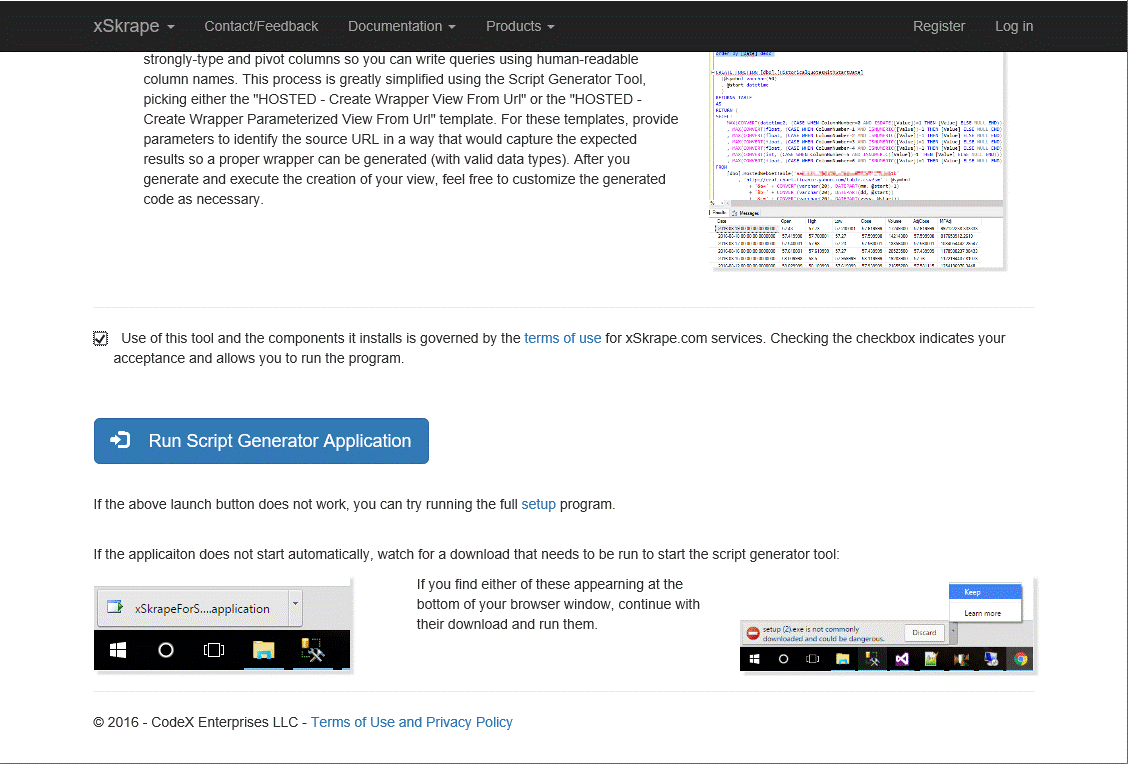
(Either of those methods to launch the application might cause your browser to download a file, which you’ll need to click on to run manually.)
The Script Generator requires you to set a database connection by clicking on the “Set Connection” button. You can specify a server and database, as illustrated here:
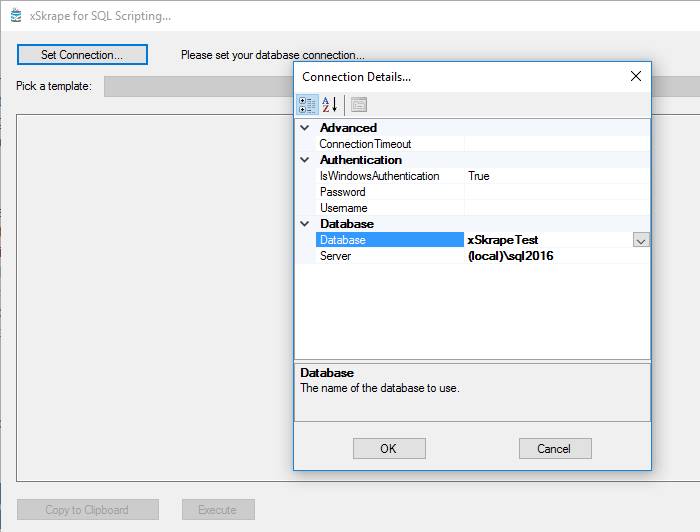
Next, select the “Enable xSkrape for Database” template in the drop-down list and click the “Create Script” button. You’ll be asked for the schema name to use to house the xSkrape objects that will be added. The default is “dbo”, but you can provide the name of a different (pre-existing) schema if you like. Clicking OK, you’ll be given the following alert:
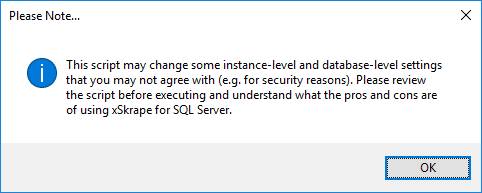
This is important since the resulting script contains commands that a) require elevated permission to execute, b) may change settings at both instance and database level related to security. We suggest you review the generated script showing in the preview window. You can execute it for the selected database by clicking the “Execute” button and should see:
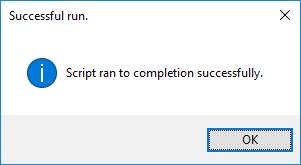
Note: Running the “Enable xSkrape for Database” template can be used to also update the xSkrape CLR assemblies to a newer version, when they become available.
Next, we’ll add a new parameterized view (aka table-valued
user-defined function) that wraps the content of tabular data we find at
the URL: https://www.quandl.com/api/v1/datasets/WIKI/MSFT.csv?sort_order=desc&collapse=daily&trim_start=2016-01-01
In this case, the text “MSFT”
is a stock symbol that we can parameterize,
along with the trim_start date parameter – we’ll do
this after we’ve generated the wrapper.
To create the wrapper, we
can use the Script Generator, already running, picking the “HOSTED – Create Wrapper
Parameterized View From Url”
template and clicking “Create Script”. We’re prompted for a number of
parameters:
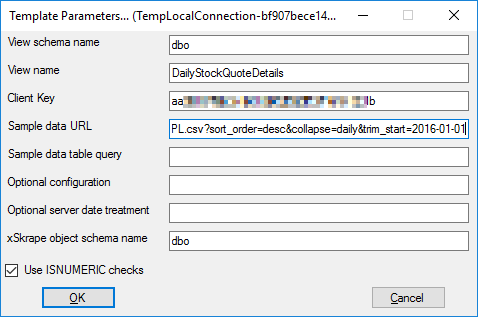
We’ve filled in the view’s
name and provided a client key code that’s linked to our xSkrape.com account.
To find this, log into your xSkrape.com account and go to the My Account -> Queries menu
option:
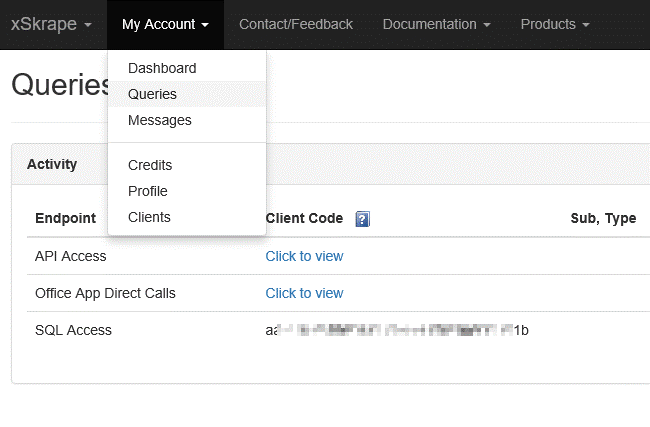
Clicking on “Click to view”
reveals the client access key associated with the corresponding query endpoint – you can use any endpoint, but
we provision new accounts with a “SQL Access” endpoint to help you identify
traffic associated specifically with xSkrape for SQL Server. Be sure to keep
your client key safe since this represents the means by which we track usage
and perform billing.
In the parameters pop-up,
we also provide the full URL that would, without modification, produce the data
set we’d ultimately expect to come from the newly created wrapper (i.e. columns
with proper data types). In this example, we include really any stock symbol (i.e. MSFT is fine),
and we’ll change that later to allow any
symbol to be passed in, instead – effectively parameterizing the wrapper.
After clicking OK, some
T-SQL is generated and shown in the preview area. You can copy it or execute it
directly from the Script Generator. If we click “Execute” and go look for the
object using SQL Server Management Studio, we find that it’s been created here:
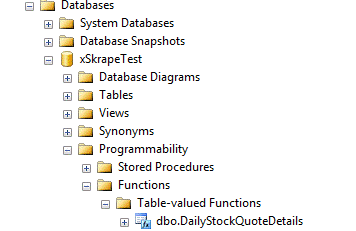
Let’s script the object as
an ALTER so we can update it:

Notice that what was generated includes a call to HostedWebGetTable with the client access key and URL we provided to the Script Generator. This can be considered a starting point, if we like. At this point we can tailor the code to look like this:
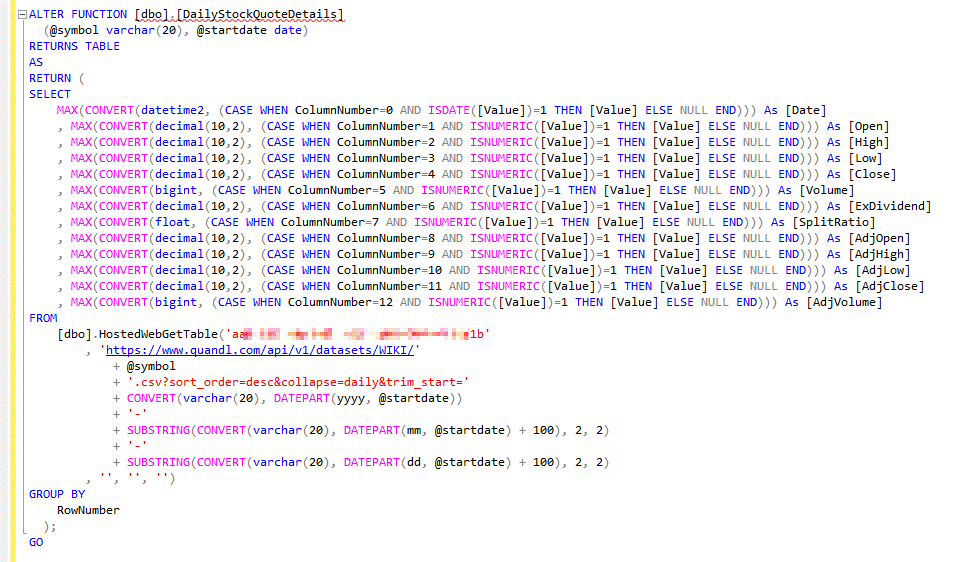
Here we’ve added @symbol as a parameter, along with a @startdate, since filtering at the data source will help with both performance and potentially reducing our credit usage (which is based on data size). We’ve also tweaked the data types involved, with the main disadvantage being if we were to re-generate the view from the template, we’d have to reapply any customizations, by hand.
Let’s write a more sophisticated query that uses both the new table-valued function and a direct call to HostedWebGetSingle to add extra details based on data that comes from the FINRA web site, related to short volume activity. An example of the FINRA data is shown here, with one file generated per day:
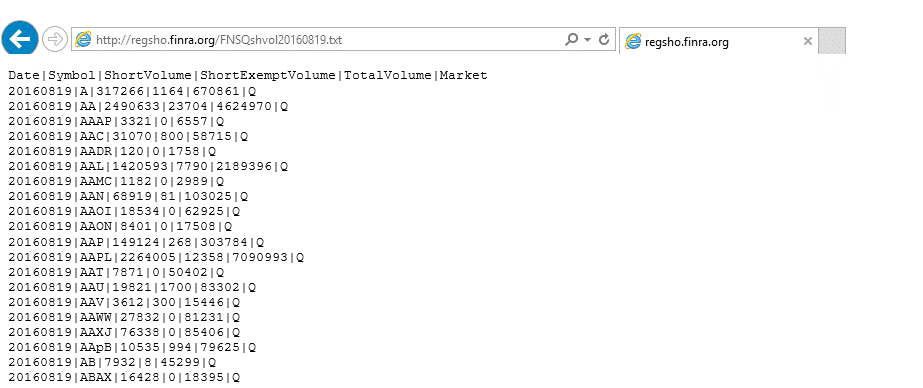
There are a couple of ways to approach parsing this data, which is pipe-delimited. In our example, we’ll use regular expressions to data scrape the first and third number that follows the symbol of interest, which represents the daily short volume for the stock (as reported to FINRA) and total volume. With these two numbers in hand, we can arrive at a basic short ratio, by day, which we present along-side price details returned from the generated table-valued function, as illustrated here:
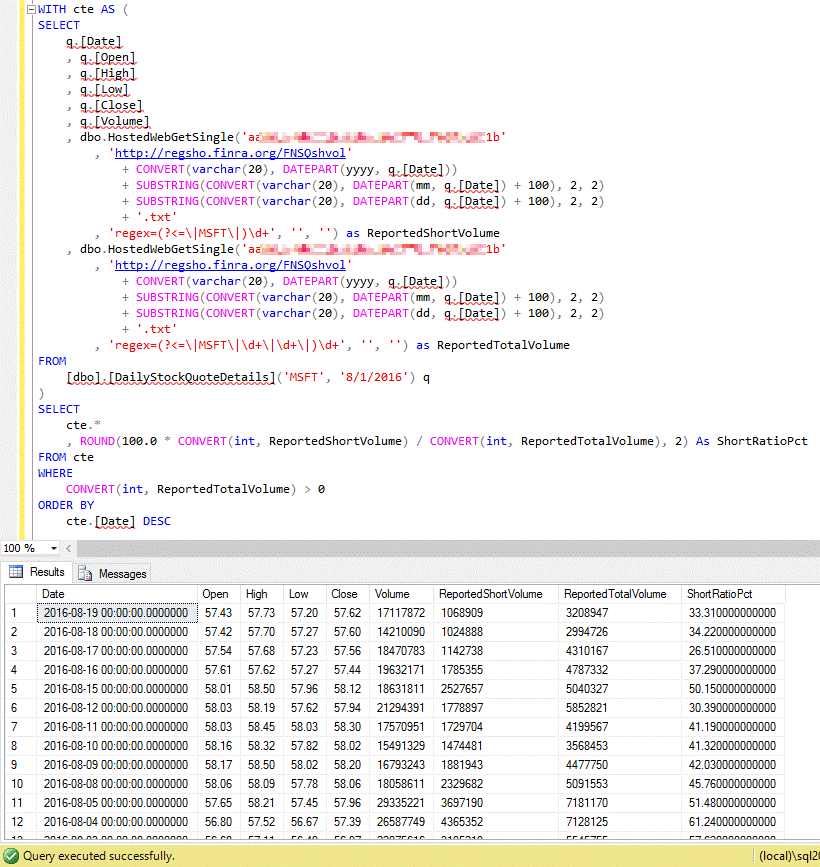
Let’s take it one step further and join to a table that’s contained in our database that lists stock symbols, thus getting a summary, by symbol, for average price over the last 5 trading days. We’ve also created our own user-defined function wrapper for our HostedWebGetSingle calls to get FINRA data, to make our T-SQL more succinct (plus we can hide our client access key inside the UDF).
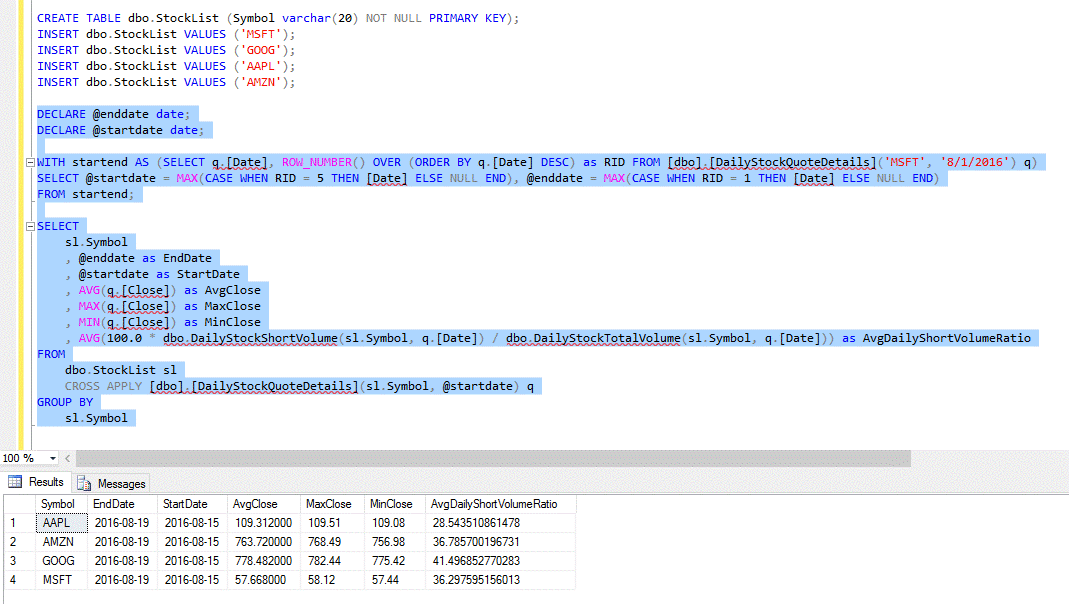
As this illustrates, we can build complex queries using live data, as if it were present locally – and we did so with effort mainly focused on building queries that deliver our final result, as opposed to explaining how to get our external data.
Let’s look at an example of a Web API that’s publicly available from USGS. This data feed returns earthquake data reported within the last day, in JSON format. Here’s an example of what the raw data looks like at http://earthquake.usgs.gov/earthquakes/feed/v1.0/summary/all_day.geojson:
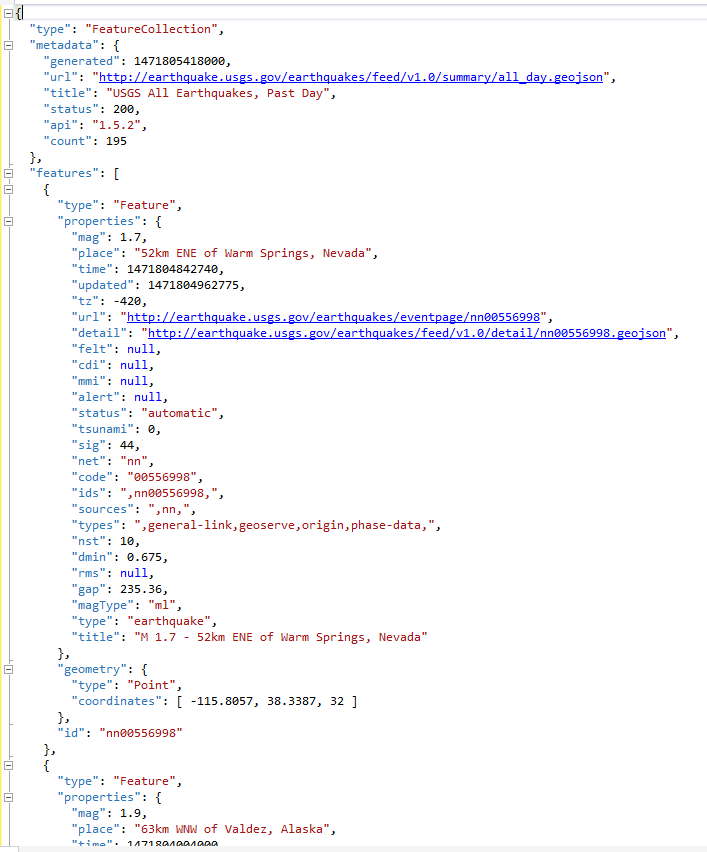
As you can see, there’s a lot of detail that we might ordinarily expect we’d have to map in order to describe what we want. With xSkrape, we have a simpler approach: we’ll create a view wrapper with nothing more provided than the source URL:
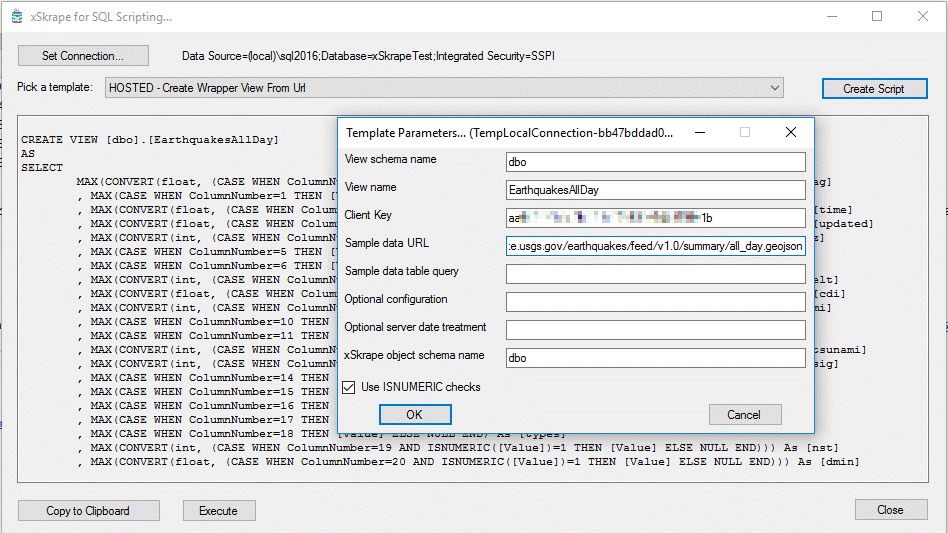
If we query the resulting wrapper, we can see plenty of detail that xSkrape was able to infer as our “likely data of interest.” It’s important to note that if we didn’t want this detail – maybe detail at a different part of the JSON hierarchy – we can control that by providing mapping details using the XS.QL language. In this example, even though xSkrape has inferred more columns than we’re actually interested in, let’s assume we’re fine with just the columns: net + code (natural key), mag, title, rms and dmin. Let’s further assume we’d like to accumulate this data on an on-going basis. We could construct an ETL task that loads this data, perhaps a few times per day, adding missing rows and updating existing ones. We won’t delete anything, though, since by nature, the data feed is only showing the “last day” worth of data, and earthquakes will drop off the list by design, at the source. We’ll also include a Created/Updated date to get more detail about the accumulated rows, in our persisted table.
We can accomplish this entirely with one MERGE statement:
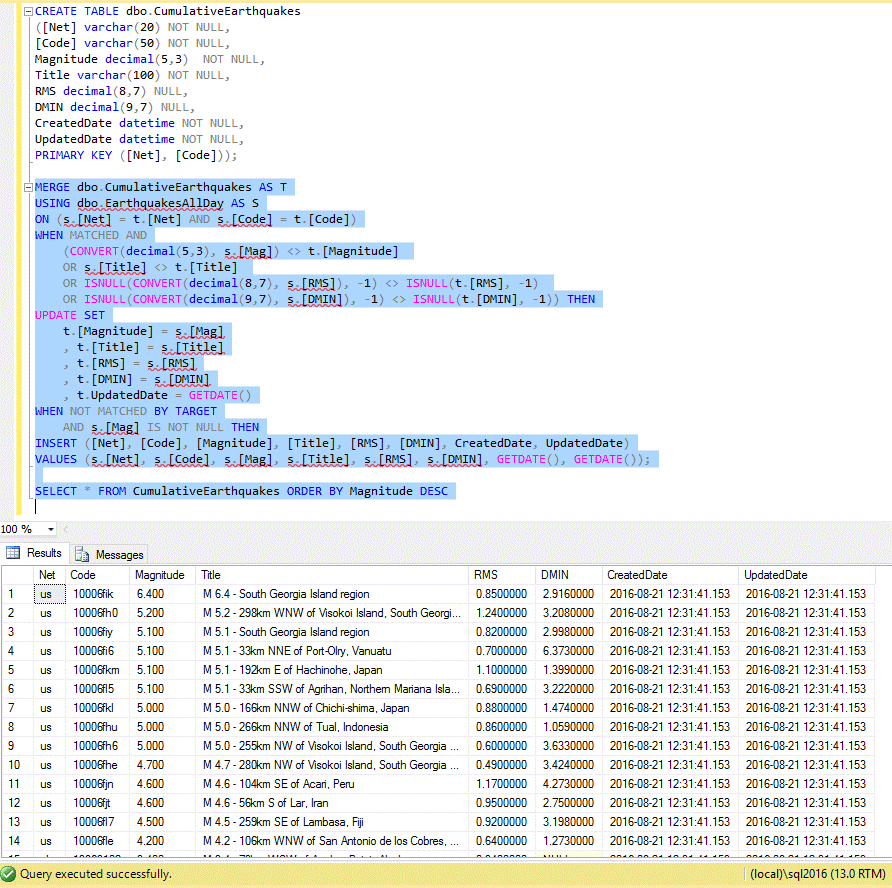
That’s it: one MERGE statement, and we’re aggregating data from a web source into a SQL table!
- Opens the door to new possibilities, yet envisioned. You may have systems today that could be enhanced to access external data sources, but you’ve so far assumed this effort would be costly and hard. As we’ve illustrated through examples, this might not be the case going forward.
- Leverage proven technology. xSkrape covers many bases: for example, merging data across multiple requests – and the XS.QL language is built to make describing what you want easy, compared to many alternatives. For example, instead of needing to use a complex XPath expression to scrape data from an HTML page that might change in structure, why not simply use “wordsfollowafter” or “numberwithsuffixfollowsnear” which are easy to understand and aren’t as sensitive to formatting changes in the source document.
- Avoids issues with latency. xSkrape can turn data that was formerly available perhaps infrequently into data available in its most current form, right when you need it in a larger SQL query.
- Avoids issues with complexity and cost. Using simple steps and a declarative way of describing your data of interest, you can query remote data using a single function call, or see it as if it were a table in your database. If your source changes, your surface area impacted is limited. For example, if the source renames a column you’re interested in and you’re using a wrapper view, you can change the wrapper and keep your original name using a column alias, meaning consumers of your wrapper view could have zero impact.
- Performance. Use of the “get table” function always turns into a remote scan, and the “get single” functions are evaluated, per row – both leading to performance considerations. We emphasize “considerations” since you’ll need to think about what situations warrant any performance cost imposed by use of these functions: some will be fine and some may not be. For example, including use of “get single” functions over 10,000 rows, hitting different pages – will be necessarily slow and so may not be a good idea for a search screen query. (Then again, returning 10,000 rows for a search may have other issues like usability!) However, using a background job that issues the same query may be fine, or using a threshold row count before merging from an external source in your app queries may work too. As is often the case with SQL, there’s usually five different ways to solve any problem and at least you have more choices by having xSkrape available. (By the way: we have a lot of experience in solving performance problems. Feel free to contact us about your problems.) Also - look for more performance optimizations we’ll be including, coming soon.
- Security Policies and use of SQL CLR. Some organizations choose to avoid using SQL CLR capabilities as a general rule, so if that’s you – xSkrape for SQL isn’t an option (except perhaps if an exception can be made!). You must also flag databases that use xSkrape as TRUSTWORTHY and have enough rights to make those kinds of changes. Also, this isn’t an option for SQL Azure, since that platform no longer supports CLR assemblies (at least for now).
- Vendor dependence. Yes, we’re really admitting this! The concern shouldn’t be with xSkrape or CodeX specifically, but whether you’re willing to let an outside party make choices about future features and direction. We will say, however, that if you follow what we’ve been doing to improve xSkrape over time, we’re on a good path to not only fix and improve the product, but offer support and a vision that emphasizes customer value. It’s also worth noting that there’s a high level of compatibility between the “hosted” and “non-hosted” versions of xSkrape for SQL Server, meaning you could in theory switch from the hosted version to the version supported by SQL-Hero with only minor changes. The non-hosted version is an owned option, meaning you would have control over the binaries involved (e.g. you could choose to never upgrade after a certain point).
Q: The client access
key is clearly very important for billing purposes. How should it be secured?
Although the templates provided create wrapper views that embed your client access key, we suggest you store these in a manner that keeps them “secure enough” for your needs. This might mean anything from leaving them in plaintext since you have a small, trusted team, all the way up to having multiple keys (e.g. development versus production) that are encrypted and decryption is based on credentials such that developers would only ever be able to access the development key. Keep in mind that your xksrape.com account which your keys are linked to allows you to inactivate the account, impose daily usage limits (requests and credit usage), usage tracking, and more.
Q: What happens if my
data source changes in a way that it no longer returns data in the same “shape”
or location?
If you’re using XS.QL features that let you identify data declaratively, you have a better chance of a structural change not impacting you. However, if it does you’ll need to watch for this since it can surface as an error message, a shift in columns receiving data (which could look incorrect and lead to errors), or simply no data. We’re considering adding new capabilities to xskrape.com which would allow you to identify queries of interest and get proactive email alerts if there’s a change that might impact your queries of interest. Those types of features are something we’ll do based on feedback, so fire away!
Q: What sources are allowed
to have data scraping against them?
As explained in our Terms of Use, you need to pay attention to all sources and respect their own Terms of Use. We discuss the issues related to screen scraping on our web site.
As you can tell, xSkrape for SQL Server goes well beyond traditional screen scraping – although that’s supported too. With the ability to turn virtually any web API into a “SQL queryable” data source using zero lines of code (and configuration in many cases), you can certainly think outside the box in building new solutions or improving existing ones.
You can start using xSkrape for SQL Server for free today: visit xskrape.com to set up an account, and visit the xSkrape for SQL Server page to run the Script Generator tool which as covered in the examples is a key starting point.
Did you like this article? Please rate it!