Building Sample Data Sets Using xSkrape
“It's easy to justify the cost savings to generate a very large data
set using xSkrape”
What can we do with sample data and why would we want to
generate it in Excel? Some possibilities include:
· Create data that we can experiment with.
· Create a data set that resembles what we think might be realistic in the future (i.e. we might not have comparable data today), and we would like to demonstrate it to others.
· Modeling situations when we don't have a complete data set (i.e. we may want to augment an existing data set, and adding completely random data would make it look "weird").
·
Use it for creating "test data" that
can be imported into other product such as SQL databases, where it becomes
usable for testing (e.g. stress testing, unit testing, etc.) or demonstration
for all the reasons described above. For our purposes, we talk about
"sample data" and "test data" interchangeably since xSkrape
as the means to generate them is the same for either case.
Using the approach described here to obscure existing data
(aka data obfuscation) is also possible and is covered in a different article.
How easy is it to use the xSkrape for Excel add in to
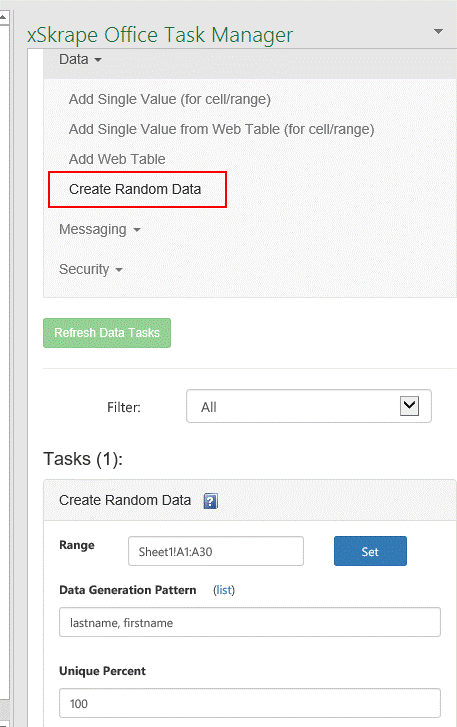
generate sample data? Extremely easy! For example, here we've added a data
creation task and configured it to populate a cell range using lastname, firstname as our data generation pattern, and
requiring that all generated names be unique (100% uniqueness):
If we click on the "Create" button or the “Create
Random Data” button on the Excel toolbar:
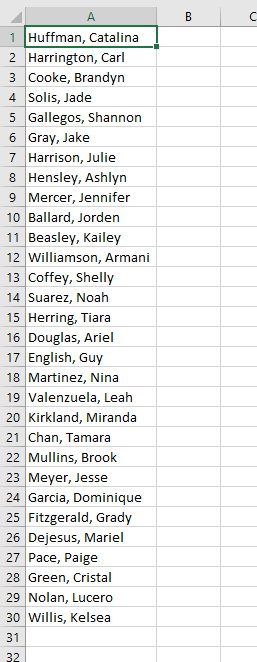
Then we would see data that looks like this:
If we added a second data generation task that uses the
pattern {"numberfrom":"20",
"numberto":"100", "precision":"2",
"exponent":"0.3"} and execute it, our data now
looks like this:
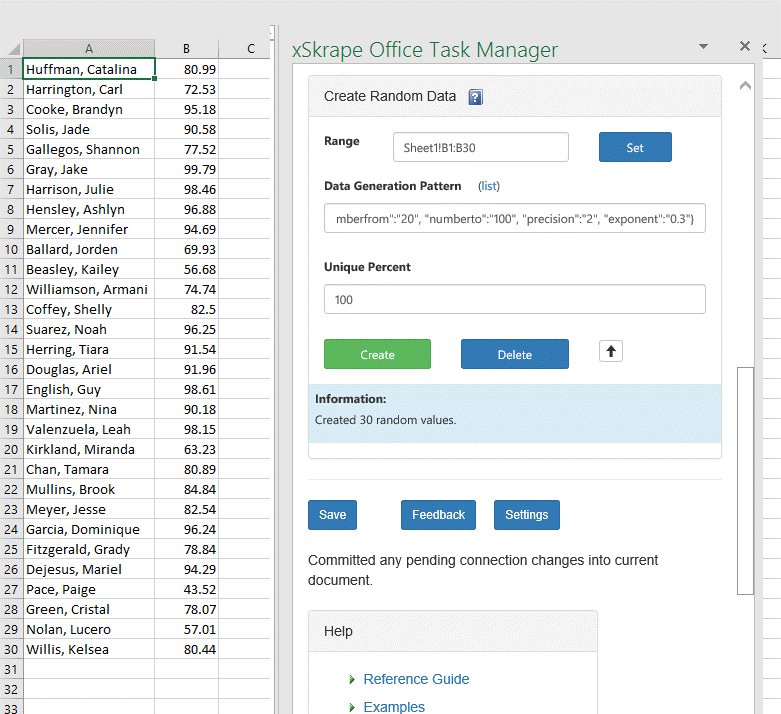
Of note from this example:
· The use of "precision":"2" means we get two decimal places, which could be used as a currency value.
·
The use of "exponent":"0.3"
means we favor numbers closer to 100 than 20. This might match a scenario where
say the number represents a price paid for an item we sell, where it's more
common to sell items that are higher in value. The evidence this works can be
seen by applying this task to a number of cells and looking at the average
value as shown here:
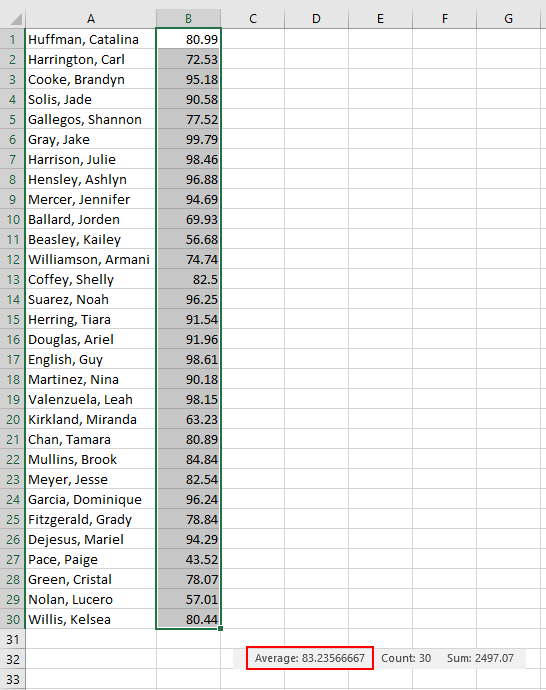
We can see that the average is 83.2 where if values were
distributed evenly, the expected average would be closer to "60" (the
mid-point between 20 and 100).
The "language" used here to describe what should
be generated is documented
fully on our web site and as more features are added, this documentation will
evolve.
You may wonder: "This isn't too complex - I could
probably write some code that would create this kind of sample data
myself." Let's examine that premise.
Let's assume you're interested in data that's similar to
what you could get from xSkrape: realistic names, control over distributions of
numbers and dates, etc. As such, we'd expect this is task that might take a few
hours, not a few minutes.
Next, how much is your time worth? Maybe $80/hour? That's
likely a conservative estimate, but if we go with that, you could purchase
60,000 xSkrape credits for 3 hours of your time over-and-above the relatively
small amount of time you'd need to set up one or more xSkrape data creation
tasks.
With 60,000 credits available, you could generate 6,000,000
data values. (This is at prices as of 8/13/2016.) If you had a table with 6
columns, that's a million rows of
data.
In other words, it's easy to justify the cost savings to
generate a very large data set using xSkrape. Not to mention incremental
improvements in our obfuscation language, support and other excellent feature
areas.
You can use xSkrape data generation for free when you only
need a reasonably small amount of test data. Current rates imply you could
generate 25,000 data values for free, per month.
Also check out the test data generation capabilities in our SQL-Hero tool: you can
do very similar things to what we've described here, but import generated data
directly to your SQL Server database quickly (using bulk insert), respecting
referential integrity, check constraints & parent-child relationships, with
automation options, and more! We cover some practical applications of data
generation for SQL-Hero in a different whitepaper.
Does this all seem interesting but too complicated to implement yourself? Feel free to contact us about consulting options.
Did you like this article? Please rate it!